Report Data Processing and Storage
Author: Ahmet Selman Güclü
Overview
The report data processing system transforms PDF reports into structured data stored in MongoDB. Each report is processed in two ways:
- The complete report content is split into meaningful sections
- An AI-generated summary is created for the entire report
All report data is stored as text in the database.
Report Configuration
Reports are configured in reports_utils.py, which maintains:
- A list of available country reports with their URLs and country names as well as predefined report sections that are common across all countryreports:
COUNTRY_REPORTS = [
{
"url": "https://static.hungermapdata.org/insight-reports/latest/hti-summary.pdf",
"country_name": "Haiti",
},
# ... other reports
]
REPORT_CHUNKS = [
"FOOD INSECURITY AT A GLANCE",
"Current food security outlook",
"Regions with the highest prevalence of insufficient food consumption",
# ... other sections
]
- A list of Year in Review reports with their URLs and corresponding years:
YEAR_IN_REVIEW_REPORTS = [
{
"url": "https://static.hungermapdata.org/year-in-review/2023/Global.pdf",
"year": 2023,
},
# ... other reports
]
Processing Steps
The system uses two different parsers depending on the report type:
Year-in-Review Reports (year_in_review_parser.py)
- Downloads the PDF from the year-specific URL
- Identifies sections based on font size (headings)
- Processes content page by page, maintaining heading context
- Saves the processed content in both CSV and JSON formats
Country Reports (report_chatting_data_parser.py)
- Downloads the PDF from the provided URL
- Attempts to split the content into predefined chunks based on common sections
- Falls back to page-by-page splitting if chunk detection fails
- Saves the processed content in both CSV and JSON formats
def parse_pdf(country_name: str, url: str):
"""
Parse the pdf file from the url and write the structured data to CSV and JSON files.
"""
# Create directory for report content data
report_data_dir = os.path.join(SRC, "assets", "report_content_data")
os.makedirs(report_data_dir, exist_ok=True)
# Process PDF content
pdf_document = fitz.open("pdf", pdf_content)
for page_number in range(len(pdf_document)):
page = pdf_document[page_number]
page_text = page.get_text()
# Try to find standard sections
for title in TITLES:
if title in page_text:
# Extract and save section content
content = extract_section(page_text, title)
save_to_files(content)
This chunking approach significantly reduces token usage (for GPT-4o) compared to processing whole reports:
| Process | Token Usage | Reduction |
|---|---|---|
| Whole Report | 2,800-5,400 | - |
| Chunked | 90-540 | Up to 93% |
2. AI Summary Generation
The report_summarizer.py creates comprehensive summaries of reports to enable better responses to high-level questions and overview requests. While chunked data is excellent for specific queries, summaries are crucial for:
- Answering general questions about the report
- Providing complete report overviews
- Maintaining context when users ask for summaries
- Offering holistic insights that might be lost in chunked data
def create_summary(country_name: str, report_content: str, regenerate: bool = False) -> Dict:
"""
Generates a summary of the report using OpenAI API and saves it as CSV and JSON.
"""
# Generate summary using OpenAI
system_prompt = """You are a professional analyst skilled in creating concise yet comprehensive
report summaries."""
user_prompt_template = f"""Please create a comprehensive summary of the following
{'Year in Review report for' if report_type == 'year_in_review' else 'report about'} {identifier}.
Focus on the key findings, statistics, and important trends.
The summary should be well-structured and maintain the most critical information from the report.\n\n
Report Content:\n"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt_template + report_content},
]
response = openai.chat.completions.create(
model=MODEL,
messages=messages,
temperature=0.7,
)
# Prepare summary data with explicit summary identifier
title_prefix = "Year in Review" if report_type == "year_in_review" else "Report"
summary_data = {
"title": f"{identifier} {title_prefix} Summary",
"summary": f"The following is a complete summary of the {title_prefix.lower()} for {identifier}:\n\n"
+ response.choices[0].message.content.strip(),
}
# Save as CSV and JSON files
save_to_files(summary_data, country_name)
return summary_data
Content Identifiers
Since user prompts are of a semantic manner, no conventional pre-filtering can be done on the reports data, for example to only use entries for a specific page.
Consider a prompt like this: Can you explain the diagram on page 4?
To be able to still handle such queries, both summary and chunked content include specific identifiers which are added at the very beginning of their contents:
-
For Summaries:
"The following is a complete summary of the whole report for {country_name} / {year}:" -
For Country Report Chunks:
"THIS CONTENT IS PART OF PAGE {page_number}:" -
For Year-in-Review Chunks:
"THIS CONTENT IS FROM PAGE {page_number} AND CONTAINS THE CONTENT FOR THE FOLLOWING HEADINGS: {headings}" -
For Whole Pages (not-chunked)
"(this content is the whole page {page_number})"
These identifiers are crucial for the similarity search functionality, allowing it to:
- Match general queries with summary content
- Find page-specific information when requested
- Distinguish between different types of content (summary vs. chunked)
- Provide more accurate and contextual responses
3. Database Upload
The system uses specialized upload scripts for each type of content:
db_upload_report_chatting_data.pyfor country reportsdb_upload_year_in_review_report_data.pyfor year-in-review reportsdb_upload_report_summary.pyfor both types of summaries
Each script processes data into a consistent structure with type-specific fields:
For Country Reports
{
"document_name": f"{country_name} Report Content",
"country_name": country_name,
"document_title": title,
"data_labels": ["reports_data"],
"data_description": f"Content extracted from the report of {country_name}.",
"document_page_number": page_number,
"data": content,
}
For Year-in-Review Reports
{
"document_name": f"{year} Year in Review Report Content",
"year": year,
"document_title": title,
"data_labels": ["year_in_review_data"],
"data_description": f"Content extracted from the {year} Year in Review Report.",
"document_page_number": page_number,
"data": content,
}
For Summaries
{
"document_name": f"{country_name} Report Summary",
"country_name": country_name,
"data_labels": ["reports_summary"],
"data_description": f"AI generated summary of the report of {country_name}.",
"data": data.get("summary"),
}
4. Batch Processing
The upload_all_reports.py script orchestrates the entire process. This means that for uploading or updating the data in the database it is enough to only run this script rather than going all the previous steps individually.
The script:
- Processes all configured reports in
reports_utils.pysequentially - Handles both content and summary uploads to the
report_chattingcollection - Creates vector embeddings for similarity search
def run_reports_upload():
content_module = folder_path.replace("/", ".") + ".db_upload_report_chatting_data"
summary_module = folder_path.replace("/", ".") + ".db_upload_report_summary"
year_in_review_module = (
folder_path.replace("/", ".") + ".db_upload_year_in_review_report_data"
)
for report in country_reports:
country_name = report["country_name"]
# Upload report content
subprocess.run([python_executable, "-m", content_module, country_name])
# Upload report summary
subprocess.run([python_executable, "-m", summary_module, country_name])
# ... existing code
for report in year_in_review_reports:
# ... upload report content
# ... upload report summary
By default, the script will not re-generate a new AI generated summary for a report if one exists already. However, if it is wished to do so the following part can be modified with an additional flag in run_reports_upload:
summary_upload_result = subprocess.run(
[python_executable, "-m", summary_module, country_name, true], # add a true flag here
capture_output=True,
text=True,
)
This approach ensures that no unnecessary costs occur for generating AI summaries when they already exist
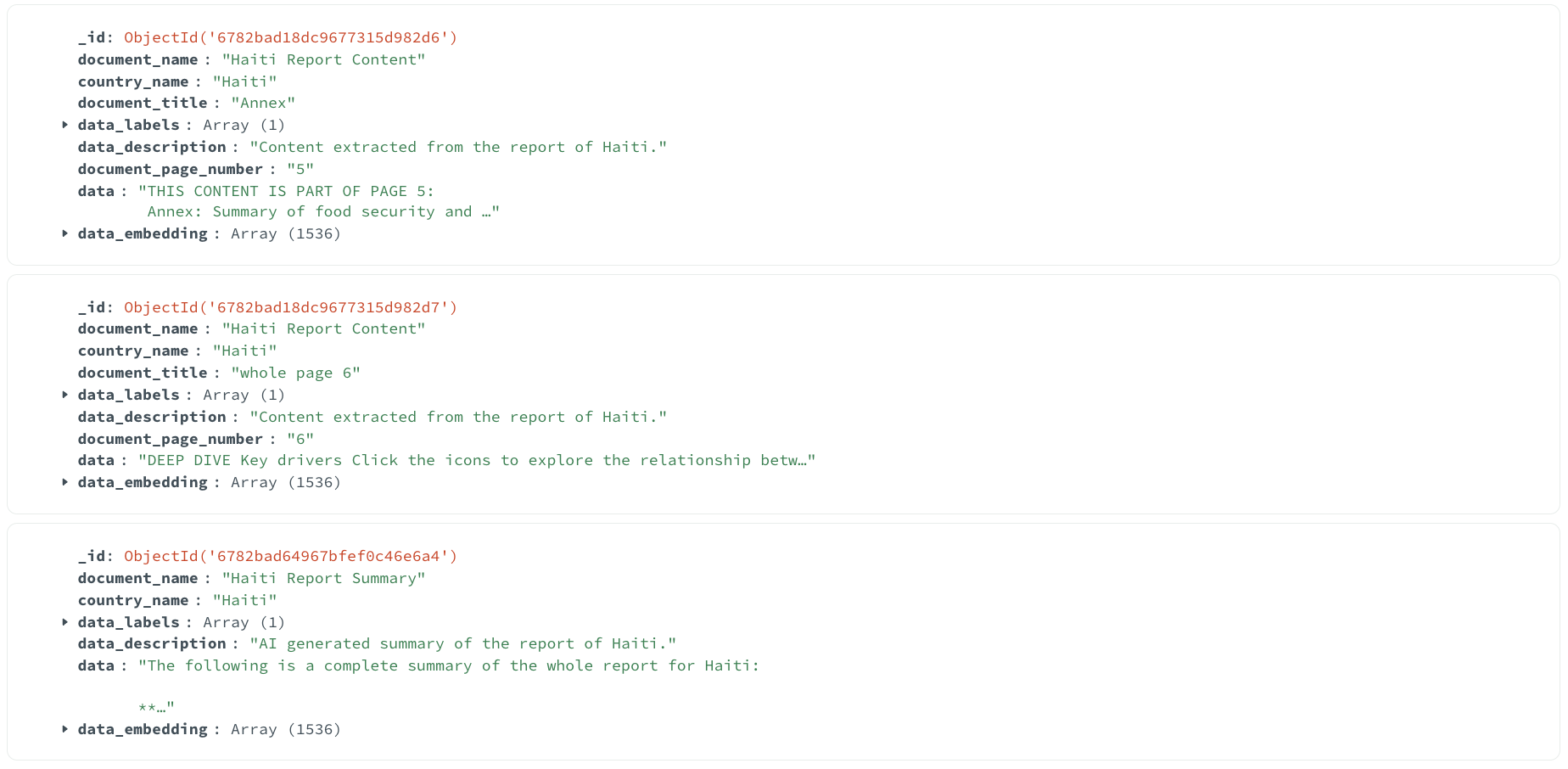
Database Structure
All in all, the MongoDB report_chatting collection will contain three types of entries:
- Multiple Chunks per Country Report document. For example
Current food security outlookforHaiti Report Content - Multiple Chunks per Year-in-Review report document. For example
Januar-Februaryfor2023 Year in Review Report - One AI generated summary per document.
Here's a look into some entries of the database:
This structured approach ensures:
- Effective similarity search through vector embeddings
- Easy maintenance and updates of report data
- Clear separation between report content and summaries
- Effective data retrieval during chat interactions with low token costs and high quality results